Sobel operator
| Feature detection |
|---|
|
Output of a typical corner detection algorithm
|
| Edge detection |
| Canny · Canny-Deriche · Differential · Sobel · Prewitt · Roberts Cross |
| Interest point detection |
| Corner detection |
| Harris operator · Shi and Tomasi · Level curve curvature · SUSAN · FAST |
| Blob detection |
| Laplacian of Gaussian (LoG) · Difference of Gaussians (DoG) · Determinant of Hessian (DoH) · Maximally stable extremal regions · PCBR |
| Ridge detection |
| Hough transform |
| Structure tensor |
| Affine invariant feature detection |
| Affine shape adaptation · Harris affine · Hessian affine |
| Feature description |
| SIFT · SURF · GLOH · HOG · LESH |
| Scale-space |
| Scale-space axioms · Implementation details · Pyramids |
The Sobel operator is used in image processing, particularly within edge detection algorithms. Technically, it is a discrete differentiation operator, computing an approximation of the gradient of the image intensity function. At each point in the image, the result of the Sobel operator is either the corresponding gradient vector or the norm of this vector. The Sobel operator is based on convolving the image with a small, separable, and integer valued filter in horizontal and vertical direction and is therefore relatively inexpensive in terms of computations. On the other hand, the gradient approximation which it produces is relatively crude, in particular for high frequency variations in the image.
Contents |
Simplified description
In simple terms, the operator calculates the gradient of the image intensity at each point, giving the direction of the largest possible increase from light to dark and the rate of change in that direction. The result therefore shows how "abruptly" or "smoothly" the image changes at that point, and therefore how likely it is that that part of the image represents an edge, as well as how that edge is likely to be oriented. In practice, the magnitude (likelihood of an edge) calculation is more reliable and easier to interpret than the direction calculation.
Mathematically, the gradient of a two-variable function (here the image intensity function) is at each image point a 2D vector with the components given by the derivatives in the horizontal and vertical directions. At each image point, the gradient vector points in the direction of largest possible intensity increase, and the length of the gradient vector corresponds to the rate of change in that direction. This implies that the result of the Sobel operator at an image point which is in a region of constant image intensity is a zero vector and at a point on an edge is a vector which points across the edge, from darker to brighter values.
Formulation
Mathematically, the operator uses two 3×3 kernels which are convolved with the original image to calculate approximations of the derivatives - one for horizontal changes, and one for vertical. If we define A as the source image, and Gx and Gy are two images which at each point contain the horizontal and vertical derivative approximations, the computations are as follows:
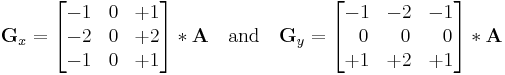
where  here denotes the 2-dimensional convolution operation.
here denotes the 2-dimensional convolution operation.
The x-coordinate is here defined as increasing in the "right"-direction, and the y-coordinate is defined as increasing in the "down"-direction. At each point in the image, the resulting gradient approximations can be combined to give the gradient magnitude, using:
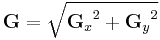
Using this information, we can also calculate the gradient's direction:
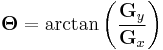
where, for example, Θ is 0 for a vertical edge which is darker on the right side.
More formally
Since the intensity function of a digital image is only known at discrete points, derivatives of this function cannot be defined unless we assume that there is an underlying continuous intensity function which has been sampled at the image points. With some additional assumptions, the derivative of the continuous intensity function can be computed as a function on the sampled intensity function, i.e. the digital image. It turns out that the derivatives at any particular point are functions of the intensity values at virtually all image points. However, approximations of these derivative functions can be defined at lesser or larger degrees of accuracy.
The Sobel operator represents a rather inaccurate approximation of the image gradient, but is still of sufficient quality to be of practical use in many applications. More precisely, it uses intensity values only in a 3×3 region around each image point to approximate the corresponding image gradient, and it uses only integer values for the coefficients which weight the image intensities to produce the gradient approximation.
Extension to other dimensions
The Sobel operator consist of two separable operations [1]:
- Smoothing perpendicular to the derivative direction with a triangle filter :
- Simple central difference in the derivative direction :
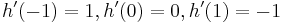
Sobel filters for image derivatives in different dimensions with 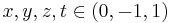 :
:
1D: 
2D: 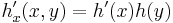
3D: 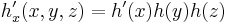
4D: 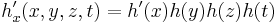
Thus as an example the 3D Sobel kernel in z-direction:
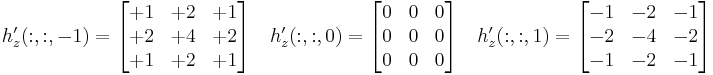
Technical details
As a consequence of its definition, the Sobel operator can be implemented by simple means in both hardware and software: only eight image points around a point are needed to compute the corresponding result and only integer arithmetic is needed to compute the gradient vector approximation. Furthermore, the two discrete filters described above are both separable:
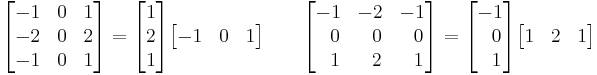
and the two derivatives Gx and Gy can therefore be computed as
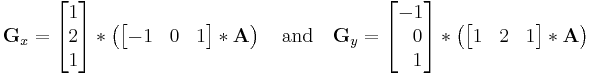
In certain implementations, this separable computation may be advantageous since it implies fewer arithmetic computations for each image point.
Applying convolution K to pixel group P can be represented in pseudocode as:
N(x,y) = Sum of { K(i,j).P(x-i,y-j)}, for i,j running from -1 to 1.
N(x,y) represents the new matrix resulted after applying the Convolution K to P. where P is pixel matrix.
Example
The result of the Sobel operator is a 2-dimensional map of the gradient at each point. It can be processed and viewed as though it is itself an image, with the areas of high gradient (the likely edges) visible as white lines. The following images illustrates this, by showing the computation of the Sobel operator on a simple image.
Alternative operators
The Sobel operator, while reducing artifacts associated with a pure central differences operator, does not have perfect rotational symmetry. Scharr looked into optimizing this property.[2][3] Filter kernels up to size 5 x 5 have been presented there, but the most frequently used one is:

Scharr operators result from an optimization minimizing weighted mean squared angular error in Fourier domain. This optimization is done under the condition that resulting filters are numerically consistent. Therefore they really are derivative kernels rather than merely keeping symmetry constraints.
A similar optimization strategy and resulting filters were also presented by Farid and Simoncelli.[4][5] They also investigate higher-order derivative schemes. In contrast to the work of Scharr, these filters are not enforced to be numerically consistent.
The problem of derivative filter design has been revisited e.g. by Kroon.[6]
Orientation-optimal derivative kernels drastically reduce systematic estimation errors in optical flow estimation. Larger schemes with even higher accuracy and optimized filter families for extended optical flow estimation have been presented in subsequent work by Scharr.[7] Second order derivative filter sets have been investigated for transparent motion estimation.[8] It has been observed that the larger the resulting kernels are, the better they approximate Derivative of Gaussian filters.
Example comparisons
Here, four different gradient operators are used to estimate the magnitude of the gradient of the test image.
See also
- Digital image processing
- Computer vision
- Edge detection
- Feature detection (computer vision)
- Feature extraction
- Image gradient
- Roberts Cross
- Prewitt operator
- Laplace operator
References
- ^ K. Engel (2006). Real-time volume graphics,. pp. 112–114.
- ^ Scharr, Hanno, 2000, Dissertation (in German), Optimal Operators in Digital Image Processing .
- ^ B. Jähne, H. Scharr, and S. Körkel. Principles of filter design. In Handbook of Computer Vision and Applications. Academic Press, 1999.
- ^ H. Farid and E. P. Simoncelli, Optimally Rotation-Equivariant Directional Derivative Kernels, Int'l Conf Computer Analysis of Images and Patterns, pp. 207--214, Sep 1997.
- ^ H. Farid and E. P. Simoncelli, Differentiation of discrete multi-dimensional signals, IEEE Trans Image Processing, vol.13(4), pp. 496--508, Apr 2004.
- ^ D. Kroon, 2009, Short Paper University Twente, Numerical Optimization of Kernel Based Image Derivatives .
- ^ Scharr, Hanno, Optimal Filters for Extended Optical Flow In: Jähne, B., Mester, R., Barth, E., Scharr, H. (eds.) IWCM 2004. LNCS, vol. 3417, pp. 14–29. Springer, Heidelberg (2007).
- ^ Scharr, Hanno, OPTIMAL SECOND ORDER DERIVATIVE FILTER FAMILIES FOR TRANSPARENT MOTION ESTIMATION 15th European Signal Processing Conference (EUSIPCO 2007), Poznan, Poland, September 3–7, 2007.